July 2020
The underlying functionality of the two utilities - maketape and tapedump - has not changed, but this implementation of the code in COBOL includes more validation of parameters specified by the user, and the full-screen interface to maketape makes it much easier to use.
Maketape will read one or more text files on a host Operating System and produce a single virtual tape image that has standard IBM labels.
Tapedump will read a virtual tape image and report the contents, in a summary format or including all data contained in the dataset(s) on the tape.
The source code for both utilites is contained in a single archive, available from my site at awsutil.cobol.tar.gz [10 kB MD5: ae7e0139c26878fde141468126526d91]. You will need GnuCOBOL installed to compile the utilities. I would recommend using the latest version (which as I write this is 3.1 rc1). You can acquire it from SourceForge or from Arnold Trembley's site. If you want to install GnuCOBOL on Windows, you must get it from Arnold's site. In fact, I would recommend Arnold's site regardless of the platform you are installing to, since there are scripts available there that make installing GnuCOBOL on Linux even easier than the SourceForge version. The Bash install script from Arnold's site will acquire and install other packages that are required for GnuCOBOL to work best.
Once you have the GnuCOBOL compiler installed, you can compile the two AWS utilities with: cobc -x maketape.cbl and cobc -x tapedump.cbl. For each of the utilities, all required subprograms are included in the base file, so there is no need to compile separate components to be linked together.
All parameters for the maketape program are entered on a full-screen panel. In a terminal window type maketape and press Enter to display the panel:
The fields in the panel are:
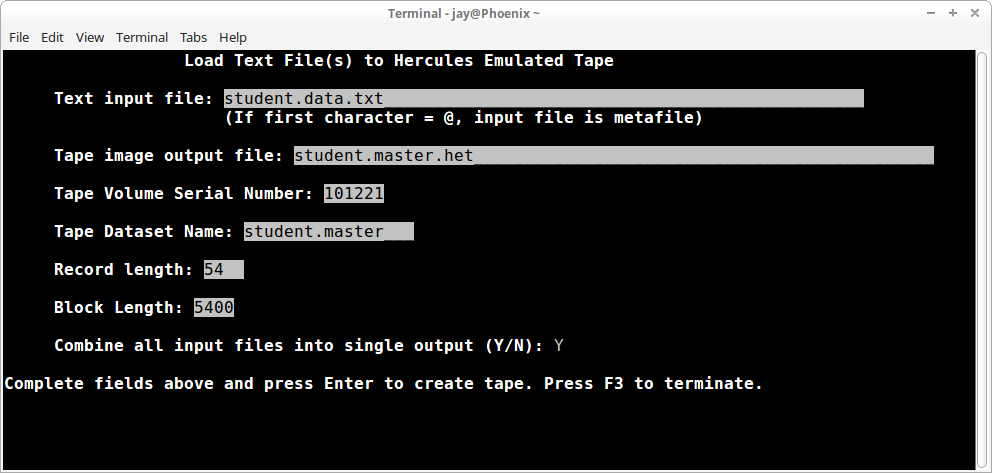
Text input file
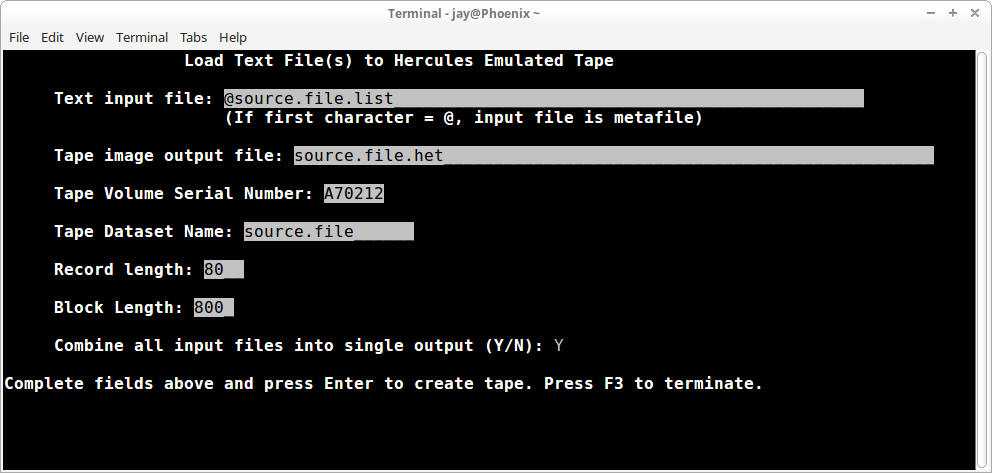
The source for the data records to be loaded to the tape image is specified in this field. If you have a group of files that are the same format that you want to load at the same time, you can create a plain text file containing the list of the files to be loaded and specify the name of that file, preceded by an at sign (@), to have maketape load the contents of all the files to the single tape image. The file name entered must be present in the directory where maketape is executed before you can leave the field.
The list of files contained in a metafile is limited to fifty (50) files. Each of the files named in the metafile must be present in the directory where maketape is executed before you can leave the field.
Tape image output file
The file to contain the tape image is specified in this field. Maketape only produces uncompressed image files, but I still recommend that you specify a file with the extension .het, because there is no reason to specify aws with the current level of Hercules code (regardless of which distribution of Hercules you are using). The file name entered must not be present in the directory where maketape is executed, or you will not be allowed to leave the field. There is no provision to overwrite an existing file.
Tape Volume Serial Number
The Volume Serial Number to be written in the standard labels is specified in this field. This field is required, although there is no validation of the information entered.
Tape Dataset Name
The MVS dataset name that is to be written in the standard labels is specified in this field. This field is required.
Record length
The logical record length of the records to be loaded is specified in this field. Although the version of maketape that I originally wrote was for the purpose of transferring 80 character card image records into MVS, you can specify any length record, up to the maximum 32,768, and maketape will process them. This field is required.
Block Length
The length of each block of records to be loaded is specified in this field. The value specified must be a multiple of the logical record length. This field is required. If you do not want multiple record blocks created, specify the record length in this field also in order to create an unblocked tape image.
Combine all input files into single output (Y/N)
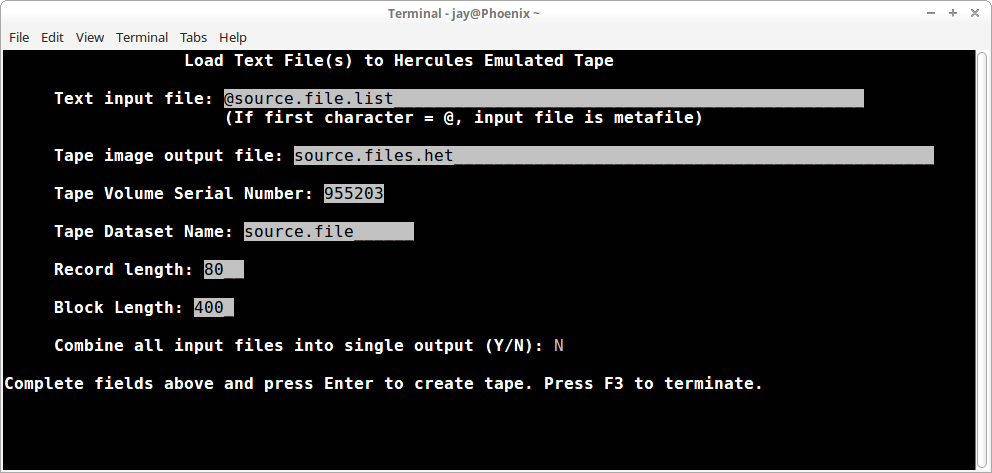
You should specify Y for this question only when multiple input files are specified, via a metafile. Entering Y will cause maketape to read all the records from all the files and write them to a single output dataset on the tape; entering N will cause the records from each input file to be written to a separate dataset on the tape. When multiple output datasets are created, a suffix is appended to the Tape Dataset Name field: .Fnnnn, where nnnn is the ascending sequence of the input file. If the appending of the suffix increases the size of the Tape Dataset Name field beyond 17 characters (the MVS limit), the last 17 characters of the resulting name will be placed in the standard tape labels. This duplicates the action of MVS when the length of a dataset name stored on tape exceeds 17 characters.
Error messages issued by maketape:
Block length must be entered, numeric, > zero Block length is required. Enter the same value as record length to create an unblocked dataset on the tape image. Block length must be multiple of record length Block length is not evenly divisible by record length. Enter a value that is a multiple of record length. Meta file contains more than 50 files The list of files contained in the specified input file exceeds fifty. Meta file #nn is not found When checking the list of files, the file in the record number displayed can not be opened for input. Option must be either Y or N The only acceptable entries are Y (designating Yes) or N (designating No). Record length must be entered, numeric, and > zero Enter the length of the largest record contained in the input file(s). Tape Dataset Name may not be blank This will be the name used to access the tape dataset in MVS, so it is a required field and must conform to MVS naming conventions. Tape image output file already exists The name entered for the output tape image file is the same as an already existing file. Tape image output file must be entered The name for the output tape image file must be entered and must conform to naming standards for your operating system. Tape Volume Serial Number may not be blank This will be the serial number used to access the tape in MVS, so it is a required field. Text input file is not found The file name entered (either a text file or metafile containing a list of text files) can not be opened for input. Text input file must be entered The name for an existing file must be entered for the input text file (or metafile containing a list of text files).
Here is an example creating a tape dataset containing the records from a single text input file. Each record in the input file is 54 bytes long and the output tape image will contain a blocked dataset with each block containing 100 records:
Here is an example creating a tape dataset containing all the records from a group of files. The metafile is source.file.list and it contains these four records:
Each record in each of the input files is 80 bytes long and all records will be read from each file and combined into a single dataset on the output tape image; each block on the output tape image will contain 10 records:
Here is an example creating a tape containing the same records as the example above, however, each input file will be copied to a separate dataset on the output tape image. For all four datasets on the output tape each block will contain 5 records. Because the length of the specified tape dataset name will allow it, the four files will be named: SOURCE.FILE.F0001, SOURCE.FILE.F0002, SOURCE.FILE.F0003, SOURCE.FILE.F0004:
There are no significant changes in the design of the tapedump program from the original version. It will provide two formats of reports of the contents of an input tape image file: a limited information report showing only the datasets contained on the tape image and an expanded report that also shows the actual data from the block header fields (the internal fields that describe the data blocks passed to an MVS program accessing the tape image), as well as the actual data contained in the blocks contained on the tape image.
Like the original version, if you execute tapedump with no parameters, it will display the required syntax:
jay@Phoenix ~ $ ./tapedump Syntax: tapedump input: | in: | i: <input file name> [ detail | d ]
The parameters will be accepted in either upper or lower case and the colon (:) following the word input (which is also accepted as in or i) is optional. If the specified file is not present in the directory where the program is invoked, you will receive an error message:
The default output is what I have always referred to as summary mode, which is really just the basic information about the dataset(s) contained on the tape image. The full output is requested by the inclusion of the word detail (which is also accepted as d).
The output from two executions of the tapedump program for all three of the tape images created above is available in tapedump1.pdf, tapedump2.pdf, and tapedump3.pdf. (The output in these files was not created in any manner using MVS, but I thought producing the output on greenbar background made it more readible, so that is why all three of these pdf files are on greenbar.)
The first output is from an execution with the summary output or no detail. The second output in each pdf is from an execution with detail specified.
You can observe by comparing the dumps of the second and third tape images the effect of combining multiple input files into a single output versus copying each input to an individual dataset. You can also observe how partial blocks are correctly written at the end of processing for a dataset.
Although not shown in any of the example outputs, tapedump sums the number of blocks read and upon encountering the EOF label set it will compare the counted blocks against the number of blocks recorded in the trailer label set. If there is a discrepancy, an error message will be printed indicating the discrepancy which includes the count of actual blocks read.
I hope that if you use MAKETAPE, you find it beneficial. If you have questions that I can answer or problems that I need to fix, please don't hesitate to let me know:

This page was last updated on September 30, 2021.