There are three ways to submit jobs to the reader for MVS.
#1 - on the regular Hercules' console, type the command:
devinit <device address> <host OS filename> <args>
<device address> is the of the card reader; for example,
0012 in the starter system.
<host OS filename> is the name of the file, possibly including a path, on
the host operating system (Linux, Windows/??, etc) that contains the Job Control
Language statements to be submitted to MVS.
<args> are optional arguments that modify the behavior of the emulated
card reader. For MVS you will certainly need to specify eof,
and you might also want to specify trunc. The emulator will usually
determine the proper coding for the file, but ascii and ebcdic may
be specified if you wish.
#2 - on the semi-graphical Hercules' console, the command letter n displays the prompt:
Select Device to Reassign
after which you type the letter corresponding to the peripheral device of the emulated card reader (usually near the top of the display - a or b, for example, and depends upon your configuration file), which causes the prompt:
New Name, or [enter] to Reload
after which you type the <host OS filename> and <args>, as described above for #1, and press ENTER.
#3 - beginning with Hercules version 2.15, Fish' socket device for the card reader allows you to designate a socket address for the <host OS filename>, so that card images may be "sent" to the emulated card reader from another program. Using either technique #1 or #2 above, you designate the socket address instead of a physical file name, for example:
127.0.0.1:3505 sockdev ascii trunc eof
where 127.0.0.1:3505 designate an address of 127.0.0.1, port 3505. You must also include sockdev as an argument, and when I use this I also include ascii and trunc. Don't forget the eof which is required for MVS.
You will then need a Perl script, netcat, or Fish' HercRdr program to "send" card images to the socket. There has been quite a bit of discussion on the list for this, so search for "sockdev" or "hercrdr" in the archives for more information.
On 30 March 2004 I added a description of the system I have devised and use that involves a custom JCL preprocessor and a shell script to submit jobstreams from inside of SPF/PC to the Hercules' socket reader. You can view that document at Submitting Jobstreams from PC Files via Socket Reader.
[July 2020] If you are using an MVS system built following my instructions/tutorial to build an MVS 3.8j system, there is a Windows bat file (submit.bat) in the mvsInstallationResources.zip and a bash shell script (submit.sh) in the mvsInstallationResources.tar.gz archive that are available on your system. These scripts may be used to submit (send) a jobstream contained in a text (ASCII) file to an MVS card reader defined in the Hercules hardware configuration as a socket device.
Well, this might not be something you would have to do often, but since I needed to and came up with a solution I thought I might as well share. In order to build a "restart" jobstream for the SMP process, I needed to be able to delete and uncatalog all of the SMP datasets on volume SMP001. Since I didn't want to type a bunch of control statements, I wrote a little awk script - scratch.awk - to generate the jobstream for me from a LISTCAT output. If you need to do this sort of thing, this ought to be a real time saver. If you are running under Windows/?? + Cygwin, you will need the gawk.exe from Cygwin.
First, run a LISTCAT -
Using an editor on your host OS (Linux/Windows/etc), cut/paste output from this job into a another plain text file. Edit scratch.awk with a plain text editor to insert the volume serial number and unit type for the volumes in the array variables in the BEGIN pattern:
BEGIN { volume[1] = "SMP001"; unit[1] = "3350"; <---- modify as needed volume[2] = "WORK02"; unit[2] = "3350"; <---- modify as needed
These are paired arrays; that is, volume[1] contains the serial number and unit[1] contains the unit type of a particular DASD volume. You can add as many volume[] and unit[] entries as you need. There are no modifications required elsewhere in order to expand/contract the arrays.
Execute the script:
gawk -f scratch.awk [file with LISTCAT output] > [file to contain generated job]
The generated job is a ready to run jobstream that uses IEHPROGM to uncatalog and scratch all datasets that were listed in the catalog as residing on one of the DASD volumes included in the paired arrays.
[July 2020] Working from MVS, you can easily used RPF or RFE options 3.4 to list a group of datasets, filtered by the High Level Qualifier, then delete them from the resulting dataset list.
Like the task above, not something you may need often, but if you do, here is a time saver. I needed to be able to make catalog entries for all datasets on a DASD volume, but didn't want to do a lot of typing. The awk script - catalog.awk - reads an IEHLIST output and generates an IDCAMS jobstream to do the task.
First, run an IEHLIST -
Include as many volumes in the single job as you need. Cut/paste output from this job into a another plain text file. Edit catalog.awk with a plain text editor to insert the volume serial number and unit type for the volumes included in the output in the array variables in the BEGIN pattern:
BEGIN { unittype["SMP001"] = "3350"; <---- modify as needed unittype["WORK02"] = "3350"; <---- modify as needed
This design exploits awk's ability to use anything as an "index" into an array. The "data" stored in the unittype array at the "index" value for the volume serial number is the unit type. You can add as many entries to this array as you need. There are no modifications required elsewhere in order to expand/contract the arrays.
Execute the script:
gawk -f catalog.awk [file with IEHLIST output] > [file to contain generated job]
The generated job is a ready to run jobstream that uses IDCAMS to create catalog entries for all datasets in the IEHLIST output existing on one of the volume serial numbers found in the unittype array.
[July 2020] Working from MVS, you can use RPF or RFE options 3.4 to list all the datasets on a DASD volume. From this list, it is relatively easy to use the C action selection code to catalog any of the datasets in the list that are not catalogued.
There is an MVS utility - IEHINITT - which may be used to initialize a tape prior to writing MVS datasets on it. But, there is a utility included with Hercules - hetinit - that is much easier to use.
Hetinit will create a blank AWS tape image, either compressed or not, with a VOL1 label written on it ready to use for output by MVS. The command syntax for hetinit is:
hetinit [-d] [host OS file name] [volume serial number]
If you omit the -d switch, hetinit will write a compressed image and the file name containing the tape should have the extension '.het'. If you include the -d switch, hetinit will write an uncompressed image and the file name containing the tape should have the extension '.aws'.
The [host OS file name] is the name of the file that will contain the tape image.
The [volume serial number] is the six character (letters and numbers) identification that will be written to the VOL1 label and is used by MVS to identify the tape.
Mike Rayborn has written an IND$FILE for MVS 3.8 using the Dignus Systems/C and made it available in the (now defunct) files section of the MVS turnkey group. From Mike's post announcing the program:
I have provided a copy of Mike Rayborn's archive for download from my site here - ind$file.zip [MD5: FB8299C89D533D32CAE983B7DBE13878]. The version in this archive is 1.0.6 dated 04/14/2003.
I have also written a very brief tutorial on using IND$FILE at: installMVS/ind$file.htm
If your intent is to back up an entire DASD volume, the simple answer is to shut down MVS and Hercules and use a host OS utility (xcopy, WinZip, tar, zip, etc) to make a backup copy of the file containing the DASD volume image.
However, if you want to back up or copy specific datasets, perhaps to transport them to another system, you need to use MVS utilities appropriate to the dataset type. I am a purist and prefer to do even volume backups using MVS utilites ... it just seems like the thing to do since we have the capability.
If you want to back up an entire DASD volume to tape, use a jobstream similar to this:
You can also use IEHDASDR to restore an entire volume backup either to the originating volume or to another volume. Note: IEHDASDR will not handle 3380 or 3390 DASD.
If you want to back up a Partitioned Dataset to tape, use a jobstream similar to this:
If you want to back up a sequential dataset to tape, use a jobstream similar to this:
[July 2020] I have written a more detailed tutorial on backing up MVS datasets at Backup and Restore.
The message:
IKF0015I-C BUF PARM TOO SMALL FOR DD-CARD BLKSIZES - COMPILATION ABANDONED.
is issued because the MVT COBOL compiler is generated with BUF and SIZE parameters that are too small for blocked input. You are probably trying to read the COBOL source from a tape or disk dataset with block sizes larger than 80. You can also receive this message if you are trying to write the generated object records to a blocked dataset. A third reason can be that you have some COPY statements that are attempting to include COBOL source from a SYSLIB dataset. The solution is to increase the REGION for the COBOL compile step significantly, say to 4096K, and to include these two entries in the COBOL PARM:
BUF=1024K,SIZE=2048K
The COBOL compiler can handle these values, it is just a limitation in the MVT System Generation that they cannot be specified there. In February, 2002 I modified the COBOL compile procedures on the compiler installation tape available for download from my site to include these parameters.
There are a couple of ways to handle this.
Greg Price has a modification to IFOX00 so that it "sees" a totally blank input record as a comment line. You can download this, as well as other MVS 3.8 modifications from his site at: https://www.prycroft6.com.au/vs2mods/.
My solution was to just write an awk script - alcblank.awk - that creates a copy of the input file and changes the blank lines to comments.
In one of the discussions about the limitations of the MVT Sort/Merge (input, output, and sort/work datasets may only reside on 2311 or 2314 DASD), a question was raised about the feasibility of using VSAM to effectively "sort" data. It can be done, although not efficiently. Even so, it may be just as reasonable/efficient as copying your unsorted dataset onto 2311 or 2314 DASD, sorting it, and copying the sorted dataset back to your preferred DASD.
A jobstream that I used is vssort.jcl. With minor modifications, it may be used to sort any sequential dataset on one or more ascending keys. In order to use descending keys, it would be necessary to programmatically construct key data based upon the actual key value that would result in the correct sequence; such a task would be way beyond simply using VSAM to re-order data.
The first step is to define an Entry Sequenced cluster to hold the unsorted data:
DEFINE CLUSTER ( - NAME ( VSSORT.CLUSTER ) - VOLUMES ( MVS804 ) - RECORDSIZE ( 158 158 ) - RECORDS( 150000 0 ) - NONINDEXED - ) - DATA ( - NAME ( VSSORT.DATA ) - )
The cluster and data names do not matter, as long as they do not duplicate the names of other VSAM object in your system. Obviously the VOLUMES parameter needs to match your system; MVS804 is a 3380 volume on my system. The RECORDSIZE should be the sum of the length of your data record plus the lengths of all key fields. There is no reason you could not process variable length datasets, but in the test of this process I used a fixed length record. Since the dataset will not be extended beyond the initial load, the space allocation need not have a secondary quantity specified.
Because the key fields must be contiguous, if you have multiple keys located in different positions of the data record, you will need to construct a single key field by copying the values from the separate locations. Obviously, if your key fields do happen to be contiguous, or you simply want to sort on a single field, you can omit the IEBDG steps used to build, and later remove, the key field. Because IEBDG will not read or write VSAM data, the output of IEBDG must be a temporary sequential dataset.
I generated 100,000 test records externally to MVS and used MAKETAPE to load them onto an AWS tape. I then used IEBDG to extract two key fields - a telephone area code in positions 131-133 and a sort name in positions 46-60 - and append them to the data record. The input data record is 140 bytes long and the output record, with the keys appended, is 158 bytes.
The third step from the jobstream - IDCAMS2 - which I do not show here, simply uses the IDCAMS REPRO command to copy the IEBDG output into the ESDS cluster.
The next step from the jobstream - IDCAMS3 - does all of the work. An Alternate Index is defined over the ESDS cluster. The keys for the Alternate Index are defined as (18 0), because the key fields were appended to the beginning of the data record and are 18 bytes long. Although I didn't expect duplicate key values in my test data, I chose not to override the default of NONUNIQUEKEY and I computed the Alternate Index RECORDSIZE to allow for 20 instances of each key. The formula to use for this computation is:
The minimum value (27) is equal to:
- 5 - a constant for overhead
- 4 - the length of the RBA, the value used to address the base ESDS record
- 18 - the length of the key from the KEYS parameter
The maximum value (103) is equal to:
- 5 - a constant for overhead
- 80 - the length of the RBA (4) times the number of non-unique keys expected (20)
- 18 - the length of the key from the KEYS parameter
Be generous with the number of non-unique keys expected, since the BLDINDEX will fail if the actual number of non-unique keys exceeds the space you have allowed for them.
Since I don't expect this ESDS and AIX to be used for anything other than "sorting" the data, I have specified NOUPGRADE.
After the Alternate Index is defined, the BLDINDEX command actually reads the ESDS data, extracts the keys, sorts them, and writes them to the Alternate Index. If there is enough virtual storage, the sort will be done without using external files. Otherwise, the two work datasets - IDCUT1 and IDCUT2 - will be used during the sort.
The last command - DEFINE PATH - relates the Alternate Index to the underlying ESDS so that the base records may be accessed through the alternate keys.
//IDCAMS3 EXEC PGM=IDCAMS,REGION=2048K //IDCUT1 DD VOL=SER=MVS804,UNIT=3380,DISP=OLD,AMP='AMORG' //IDCUT2 DD VOL=SER=MVS804,UNIT=3380,DISP=OLD,AMP='AMORG' //SYSPRINT DD SYSOUT=* //SYSIN DD * /* DELETE ALTERNATE INDEX */ DELETE VSSORT.AIX ALTERNATEINDEX PURGE /* DEFINE ALTERNATE INDEX WITH NONUNIQUE KEYS -> ESDS */ DEFINE ALTERNATEINDEX ( - NAME(VSSORT.AIX) - RELATE(VSSORT.CLUSTER) - VOLUMES(MVS804) - RECORDSIZE(27 103) - TRACKS(60 30) - KEYS(18 0) - NOUPGRADE ) - DATA ( - NAME(VSSORT.AIX.DATA) ) - INDEX ( - NAME(VSSORT.AIX.INDEX) ) IF LASTCC = 0 THEN - BLDINDEX IDS(VSSORT.CLUSTER) - ODS(VSSORT.AIX) IF LASTCC = 0 THEN - DEFINE PATH ( - NAME(VSSORT.PATH) - PATHENTRY (VSSORT.AIX))
At this point, the data is accessible in the sorted order, so if you are using a program that can access a VSAM cluster, you could just point a DD statement to VSSORT.PATH and, with consideration for the key fields that have been prepended to the data record, use the data. However, in my example jobstream, the next two steps reverse the process of placing the data records in the ESDS by first copying them to a sequential dataset and then stripping the key fields from them, yielding the original data records in the desired sorted order.
I do not show the JCL for step 5 - IDCAMS4 - which simply uses the REPRO command to copy the records from the ESDS to a temporary sequential dataset.
To reverse the work of IEBDG in step 2, another IEBDG step strips the prepended key fields. The records coming into this step are 158 bytes; the records written out are the original 140 byte records.
The final step of the jobstream - IDCAMS5 - deletes the ESDS cluster and all related objects.
The execution times for the steps on my system using the 100,000 test records were:
Step
Clock Time
CPU Time
IDCAMS1 00:00.68 00:00.01 IEBDG1 00:09.05 00:00.19 IDCAMS2 00:13.36 00:00.15 IDCAMS3 00:52.18 00:00.55 IDCAMS4 03:42.82 00:04.21 IEBDG2 00:06.53 00:00.08 IDCAMS5 00:00.84 00:00.01
It was expected that the largest amount of time would be random retrieval of the records from the ESDS under control of the Alternate Index. Even so, it may be equivalent to the time spent if you choose to copy data to be sorted to a 2314 DASD and use the MVT Sort/Merge.
See the section COBOL Identification/ Environment Divisions in my document Assembling, Compiling, Link-Editing, and Executing User-Written Programs.
The sort work datasets (SORTWKnn) have been assigned to a DASD device type other than 2314 or 2311.
The MVT Sort/Merge predates MVS 3.8, which will be obvious to those familiar with the history and lineage of IBM's mainframe operating systems. So, the most advanced DASD devices that the MVT Sort/Merge is capable of accessing is the 2314 (it will also access the smaller capacity, and older, 2311 DASD). Although several people have at least done some preliminary investigation into upgrading Sort/Merge to use later DASD, at present it is still on a long "to do" list. (If you feel comfortable with Assembler and would like to take this on as a project, I will be glad to point you to the source code for Sort/Merge ... send me an email if you are interested.)
[July 2020] The source for the MVT Sort/Merge has been loaded onto a DASD volume and is available from this site at MVT Sort/Merge from Source.
One work around for this is to use IEBGENER or IDCAMS to copy the dataset you want to sort either to an AWS tape image or to a temporary dataset on a 2311 or 2314 DASD. Since you will need to define at least one 2311 or 2314 DASD in your system on which to allocate the sort work datasets, it will certainly be easier to copy the data to be sorted there as well. After the sort step has completed (successfully), you may then use another IEBGENER or IDCAMS step to copy the sorted data back to the original dataset, replacing the unsorted data.
[March 2024]
I have installed Tom Armstrong's completely rebuilt version 1.0 of OS/360 MVT Sort/Merge. It is an understatement to say that this is a great improvement over the original OS/360 version of the program. It will now dynamically allocate sort work datasets and is capable of utilizing any DASD type that it is possible to use under MVS 3.8j. If you have SYSCPK installed, you simply need to refresh your copy to the latest version to have this Sort/Merge available to use immediately. There is a PDS on SYSCPK - SYSC.SORT.CNTL - which contains Tom Armstrong's installation verification programs and a Programmers Guide for his version of the program that may be downloaded as a binary file to a host PC to view and/or print. You may also download the documentation from my site: Tom.Armstrong.OS.360.Sort.Merge.v01.1.Installation.Guide.pdf Tom.Armstrong.OS.360.Sort.Merge.v01.1.Application.Guide.pdf.
I have also updated the install tape for the OS/360 Sort/Merge to contain Tom Armstrong's version, but most people have already migrated to using SYSCPK, and it is not necessary to reload the Sort/Merge if you have SYSCPK installed.
Recently someone asked a question about using JCLLIB to specify one or more alternate procedure libraries (other than SYS1.PROCLIB) and the catalog search order. MVS 3.8j is too primitive to support JCLLIB, but you can have alternate (private, if you prefer) procedure libraries. Here is the procedure to follow to implement and use them:
First, use IEBGENER to allocate one or more Partitioned Datasets which will become your procedure libraries. On my system, I have used SYS2.PROCLIB as the dataset name, since SYS2 prefixed datasets are the common convention for creating user versions of IBM's installation datasets.
JES uses a DD statement to access the procedure library during JCL analysis, and if you look at the JES2 member of SYS1.PROCLIB, you will see a PROC00 DD that points to SYS1.PROCLIB. You will need to modify the JES2 PROC to add a DD statement for each private procedure library you have created. Be very careful when modifying system procedures, or you could render your system corrupt and unusable. I would suggest making a backup copy of the file containing the DASD image for your System Residence volume prior to modifying the JES2 PROC. If everything goes well, you can delete the backup. Otherwise, you can restore from the backup copy and recover from any problems.
Note that the jobstream above relies upon the sequence numbers that were present in the JES2 member when I created this page. If you have RPF (or you might also just use TSO Edit, if you are comfortable using it) it is preferable to edit the JES2 procedure and add the DD card for SYS2.PROCLIB following the existing card for SYS1.PROCLIB. Following the change, the relevant fragment of the procedure should look like:
After successfully completing these steps, you will need to "cycle" JES in order for the changes to take effect. An IPL is not required ... you may just stop JES2 with the $PJES2 command and the restart JES2 with the S JES2 command on the MVS console.
In order to execute procedures from a procedure library other than SYS1.PROCLIB, you then include a JOBPARM JCL statement in your jobstream with the PROCLIB parameter:
/*JOBPARM PROCLIB=PROCnn
where you substitute the two digit number for nn that corresponds to the DD statement in the JES2 PROC for your alternate procedure library. If you have a job stream in which you want to subsequently execute procedures from the system procedure library, simply include another JOBPARM statement with PROCLIB=PROC00.
[July 2020] A usermod is available from Brian Westerman that will allow the use of dynamic procedure libraries.
These two abend codes most often mean that there is not enough virtual storage available to execute the requested program. When you receive these abend codes in a TSO session, it indicates that the region requested during LOGON, or specified as the default for the TSO User ID when it was created, is insufficient for the attempted command processor or programl. LOGOFF and LOGON again, specifying a larger region using the SIZE subcommand:
LOGON <userid> SIZE(4096)
A value of 4096 (4,096 k) is usually sufficient to execute any user program, including those utilizing VSAM, which require a larger region in order to allocate buffer space.
Note that the lack of sufficient region is frequently a result of using the TSO User ID IBMUSER, which is the default TSO User ID created during System Generation. IBMUSER has a default SIZE of 44k. This User ID is intended only to be used in the case of emergencies and for setting up new TSO User IDs. You should create one or more new TSO User IDs for routine use and refrain from using IBMUSER for anything other than emergencies. See the following for instructions on creating new TSO User IDs.
Additional TSO User IDs may be added in two ways, either interactively under TSO or by executing TSO in a batch job. If you intend to add several IDs, it will probably be easier to use a batch job, but understanding the interactive steps will help you to modify the JCL for the batch job.
Interactively Under TSO
Log on to TSO using the IBMUSER User ID. It is not necessary to increase the Region SIZE for this procedure. The default logon procedure (located in SYS1.PROCLIB and created during System Generation) does not include the DD for the dataset containing the TSO User IDs, so you must manually allocate it prior to using the ACCOUNT command. The command to allocate this dataset is:
ALLOC F(SYSUADS) DA('SYS1.UADS') SHR
Issue the ACCOUNT command to invoke the conversational program which performs the administrative functions concerned with maintaining TSO User IDs:
ACCOUNT
TSO will echo ACCOUNT to indicate the command processor has been executed. You can type HELP at any time to receive syntax and usage instructions if you need further clarification of any of the ACCOUNT subcommands.
Prior to adding new User IDs, it is a good idea to issue the SYNC subcommand. This will ensure that the Broadcast dataset (SYS1.BRODCAST), which is used to store messages for TSO Users, is correctly formatted and that the User IDs in that dataset are synchronized with the User IDs contained in the TSO User ID dataset (SYS1.UADS).
Issue the ADD subcommand for each TSO User ID you wish to add. There are a number of parameters to be supplied for each User ID. The format of the ADD subcommand is:
ADD ('userid' 'password'/* 'acctnmbr'/* 'procname') MAXSIZE('integer')/NOLIM OPER/NOOPER
ACCT/NOACCT JCL/NOJCL MOUNT/NOMOUNT USERDATA('digits')
PERFORM('digits')/NOPERFORM SIZE('integer') UNIT('name') DEST('name')
The parameters specified inside the parentheses following the ADD subcommand are the only strictly required ones, although you will probably wish to include at least a few of the optional ones, discussed further below. The value of 'userid' will become the new User ID. The value of 'password' will become the initial password, required to log on with this User ID. If an asterisk (*) is specified for the 'password' value, no password will be required from this User ID for the log on to be completed. The value of 'acctnmbr' will be the value recorded in SMF records for accounting information when this User ID is utilized. If an asterisk (*) is specified for the 'acctnmbr' value, no account number will be recorded. The 'procname' is the name of the logon procedure (in SYS1.PROCLIB) to be utilized for this User ID. If you have not created your own custom procedure, IKJACCNT should be specified as that is the default that is built during System Generation.
If MAXSIZE is specified, with an integer value for 'integer', the value of 'integer' limits the amount of storage that may be requested by the User ID during logon (by utilizing the SIZE parameter). The default is NOLIM, which means there is no limit to the size region the User ID may request.
If OPER is specified, the OPERator command may be used by this User ID to issue MVS commands. NOOPER is the default.
If ACCT is specified, the ACCOUNT command may be used by this User ID to set up or modify TSO User IDs. NOACCT is the default.
If JCL is specified, this User ID may utilize the SUBMIT command to submit batch jobs to JES2. The default is NOJCL.
If MOUNT is specified, this User ID may issue ALLOC commands that request non-mounted volumes, DASD or TAPE, to be mounted. NOMOUNT is the default.
If SIZE is specified, with an integer value for 'integer', the value of 'integer' specifies the Region SIZE that is allocated for this User ID. A reasonable value to specify for SIZE is 4096. The default is 0.
If UNIT is specified, with a DASD unit name for 'name', the 'name' specified becomes the default unit type for dataset allocations for this User ID. It is appropriate to specify the name of a DASD type for which you will have a volume mounted with the storage class of PUBLIC. The default is blanks.
The defaults for USERDATA, PERFORM, and DEST are (0000), NOPERFORM, and CENTRAL SITE DEFAULT, respectively, and are adequate for MVS running under Hercules.
Here is a screen capture of the addition of a new User ID, followed by the listing of the ID with the LIST subcommand:
account ACCOUNT sync BROADCAST DATA SET INITIALIZED AND SYNCHRONIZED add (jay01 * * ikjaccnt) oper acct jcl mount unit(3350) size(4096) ADDED list (jay01) JAY01 USER ATTRIBUTES: OPER ACCT JCL MOUNT INSTALLATION ATTRIBUTES, IN HEX: 0000 MAXSIZE: NOLIM USER PROFILE TABLE: 00000000000000000000000000000000 JAY01 DESTINATION = CENTRAL SITE DEFAULT NO PERFORMANCE GROUPS (*) (*) IKJACCNT PROCSIZE= 4096K, UNIT NAME= 3350 LISTED end READY
Batch Job
The ACCOUNT command may be issued in a "TSO under Batch" job using the following jobstream:
The commands following the SYSTSIN DD are the same as would be issued interactively under TSO. The TSO responses from the commands will appear in the SYSOUT produced when the job is submitted and run:
ACCOUNT SYNC IKJ55083I BROADCAST DATA SET INITIALIZED AND SYNCHRONIZED DELETE (JAY01) IKJ56580I DELETED DELETE (JAY02) IKJ56580I DELETED DELETE (JAY03) IKJ56580I DELETED ADD (JAY01 * * IKJACCNT) OPER ACCT JCL MOUNT SIZE(4096) UNIT(3350) IKJ56560I ADDED ADD (JAY02 * * IKJACCNT) OPER JCL MOUNT SIZE(4096) UNIT(3350) IKJ56560I ADDED ADD (JAY03 * * IKJACCNT) JCL MOUNT SIZE(4096) UNIT(3350) IKJ56560I ADDED LIST (JAY01) JAY01 USER ATTRIBUTES: OPER ACCT JCL MOUNT INSTALLATION ATTRIBUTES, IN HEX: 0000 MAXSIZE: NOLIM USER PROFILE TABLE: 00000000000000000000000000000000 JAY01 DESTINATION = CENTRAL SITE DEFAULT NO PERFORMANCE GROUPS (*)(*) IKJACCNT PROCSIZE= 4096K, UNIT NAME= 3350 IKJ56590I LISTED LIST (JAY02) JAY02 USER ATTRIBUTES: OPER NOACCT JCL MOUNT INSTALLATION ATTRIBUTES, IN HEX: 0000 MAXSIZE: NOLIM USER PROFILE TABLE: 00000000000000000000000000000000 JAY02 DESTINATION = CENTRAL SITE DEFAULT NO PERFORMANCE GROUPS (*) (*) IKJACCNT PROCSIZE= 4096K, UNIT NAME= 3350 IKJ56590I LISTED LIST (JAY03) JAY03 USER ATTRIBUTES: NOOPER NOACCT JCL MOUNT INSTALLATION ATTRIBUTES, IN HEX: 0000 MAXSIZE: NOLIM USER PROFILE TABLE: 00000000000000000000000000000000 JAY03 DESTINATION = CENTRAL SITE DEFAULT NO PERFORMANCE GROUPS(*) (*) IKJACCNT PROCSIZE= 4096K, UNIT NAME= 3350 IKJ56590I LISTED END END
[July 2020] If you are using an MVS system built following my instructions/tutorial to build an MVS 3.8j system, there is a procedure in SYS2.PROCLIB, TSONUSER, which may be used to create new TSO User IDs and will also create the required standard datasets (for containing JCL, source programs, and CLISTs) for each new TSO User ID. I have updated that procedure and have also added a companion procedure TSODUSER, which may be used to delete a TSO User ID. I have packaged both of those procedures up in a jobstream and they may be added to any system where my SYSCPK is installed. SYSCPK version 1.19 or later is required as the procedures utilize programs that are contained in SYSC.LINKLIB. Download the jobstream to add the procedures to your SYS2.PROCLIB from ../downloads/tsoprocs.jcl. The procedures may be modified as necessary for your system, ie adding or removing standard datasets applicable in your system to be created for the new user. In the TSONUSER procedure, the various settings for the TSO User ID profile in SYS1.UADS are supplied by symbolic parameters; defaults are supplied by the procedure but may be easily overridden for any specific user id being created. In the TSODUSER procedure, a symbolic parameter allows the user id profile to be deleted from SYS1.UADS while retaining datasets created for/by the user id. An output from a test run adding, then subsequently deleting, a TSO User ID may be viewed at: tsoprocs.pdf.
A TSO User session is regarded by JES2 in a manner similar to a batch job step, so there is a time limit applied to the session and when that limit is exceeded, the session is automatically cancelled by JES2 with a System Completion Code 522. In a production environment the reason for this was to prevent users from coming into work, logging their terminal onto TSO, and then leaving the session sitting idle most of the work day. Even if a user is not executing any programs under their TSO session, the session is utilizing resources that could be reallocated to other users.
There are several ways to increase the time limit and they are discussed here.
Asked on the turnkey-mvs list and answered by Greg Price:
I frequently code COND=(0,NE) on the EXEC statement in order to halt a job if any preceding steps have received a non-zero code. But by coding this condition on the JOB statement, it precludes having to code this on each EXEC statement in the job. You can also include this condition on the JOB card when you are developing a jobstream, and then "fine tune" the conditions to be checked at each step before you place the jobstream into production.
This message is issued by RPF when the current workspace size is too small for the dataset being edited. If you use FORCE to save the dataset, you will lose the records from the end of the dataset that could not be contained in the current workspace.
To increase the size of the workspace, from the primary menu select Defaults (option 0), followed by Workspace (option 1) and increase the number of lines for the workspace (the WS-SIZE field) to a value large enough to contain the maximum number of records in any dataset you plan to edit. As installed, the value of this parameter is 1,000. The minimum value that may be specified is 50 and the maximum is 59,999.
If you attempt to assemble a program that includes the more recent addressing mode switching instructions or extended mnemonics for branching, you will receive error messages and the object module will be useless. Jan Jaeger has written a set of macros that extend Assembler H (the assembler included with MVS) so that many programs that were written for later versions of MVS (or OS/390 and z/OS) may successfully assemble with Assembler H. You can install these macros in a user macro library using a jobstream from my site: mnemac.
If the reason for the B37 is that SYSUT1 is out of space, Wayne Mitchell suggested a solution (in September 2003 on the H390-MVS list)- add a POWER parameter to the EXEC statement:
//IEHMOVE EXEC PGM=IEHMOVE,PARM='POWER=9'
He said that a value of 9 will handle anything except SMP datasets, although he had used a value as high as 19. I can find no documentation of this parameter anywhere, at least in the manuals and books I have on hand. But the source code for IEHMOVE shows that the value can have a maximum of three digits, so you should be able to specify this and process some really large datasets with IEHMOVE.
There is a clever little assembler program on my miscellaneous programs page that will do this. It will reset (empty) partitioned or sequential datasets in preparation for a reload. Datasets processed by this program will appear as though they have been deleted and re-allocated, however, the overhead of scratch/allocate and uncatalog/catalog is avoided. Additionally, datasets will still reside in the original location on the volume, which cannot be assured with scratch/allocate. This allows for permanent placement of datasets even though they may require reloading. Download the installation and execution jobstreams from: Reset Dataset(s) to Empty.
This question was asked on the H390-MVS group by James Campbell. He subsequently posted his solution, which I am reproducing here:
What I came up with was a zap to one of the PLI/F CSECTS that gets (automatically) linked with your mainline; the zap replaces a SPIE SVC with a SLR 15,15. Here is the zap:NAME MYPLIF IHESAP VER 0272 0A0E REP 0272 1FFFNow, without any pgm changes, I get my SYSUDUMP from the OC4 that is occurring from my assembler subroutine plus (for the less sysprog types of folks) PLI/F still gets a chance to do his friendly thing and spit out the message:IHE012I MYPLIF ABENDED AT OFFSET 00010C FROM ENTRY POINT MYPLIF WITH CC 0C4 (SYSTEM)Thus letting the "non dump reader" types relate the "10C" offset to the PL/I line of source code that calls the assembler subroutine.
Here is a jobstream to apply the ZAP:
//ZAP JOB (SYS),'ZAP PLI/F',CLASS=A,MSGCLASS=A //ZAP EXEC PGM=AMASPZAP //SYSPRINT DD SYSOUT=* //SYSLIB DD DSN=SYS1.PL1LIB,DISP=SHR //SYSIN DD * NAME IHESAPA IHESAP VER 0272 0A0E REP 0272 1FFF //
Note: Prior to applying modifications to system control programs/modules, it is always a good idea to back them up in case you want to undo your modifications. In this case, the modification is so minor it would be relatively easy to reverse the ZAP (simply exchange the last four characters in the VER/REP control cards).
The RETURN-CODE special register may be used as both a sending and receiving field in COBOL statements. The implicit definition of this special register is:
RETURN-CODE PIC S9(4) COMP.
When a program written in COBOL begins execution, the RETURN-CODE special register is set to zero.
When a program written in COBOL calls a sub-program written in COBOL:
At the termination of the called program (a GOBACK statement is executed), whatever value has been placed in the called program's RETURN-CODE by statements in the Procedure Division of the called program is passed back to the calling program. That value is available in the calling program's own RETURN-CODE.
When a program written in COBOL calls a subprogram written in a non-COBOL language:
At the termination of the called program, whatever value has been placed in Register 15 by the called program is available in the calling program's RETURN-CODE. This is consistent with the rules of standard IBM inter-program calling and linkage conventions.
When the highest level program terminates and is written in COBOL, if the value contained in the RETURN-CODE special register is not zero when the STOP RUN statement is executed, the step ABENDS with a U??? completion code and the value that was contained in RETURN-CODE becomes the value reported as the User Completion Code.
Program A (written in COBOL) is executed by JCL: // EXEC PGM=PROGA Program A calls Program B: CALL 'PROGB'. Program B (written in COBOL) returns a non-zero return code: MOVE +44 to RETURN-CODE.
GOBACK.Program A expects the code returned from Program B and, after acting upon it, resets the RETURN-CODE: IF RETURN-CODE = +44
MOVE 'Y' TO SWITCH-B
MOVE +0 TO RETURN-CODE.Program A calls Program C: CALL 'PROGC'. Program C (written in Assembler) returns a non-zero code: LA R15,20
B R14Program A expects the code returned from Program C, but the action taken is to return control to MVS passing the value to MVS: IF RETURN-CODE = +20
STOP RUN.MVS issues U020 Condition Code for the step: IEF142I ... STEP WAS EXECUTED - COND CODE 0020
This message was posted on the main Hercules-390 discussion group, as was the answer, which was found on the Share website. The WHICHASM macro exploits differences in behavior of the Type attribute for symbolic variables to determine which version of the assembler is executing:
MACRO WHICHASM LCLA &A BE SURE IT'S NOT INITIALIZED WITH A VALUE LCLC &C BE SURE IT'S NOT INITIALIZED WITH A VALUE LCLC &TA,&TC FOR TYPE ATTRIBUTE VALUES &TA SETC T'&A SET TYPE ATTRIBUTE TO A LOCAL SETC SYMBOL &TC SETC T'&C SET TYPE ATTRIBUTE TO A LOCAL SETC SYMBOL AIF ('&TA' EQ '00').ASMH TEST FOR ASSEMBLER H AIF ('&TA' EQ 'N').HLAXF TEST FOR HI LVL ASSEMBLER OR XF MNOTE 8,'WE DON''T KNOW WHICH ASSEMBLER THIS IS' MEXIT .ASMH MNOTE 0,'THIS IS ASSEMBLER H' MEXIT .HLAXF AIF ('&TC' NE 'O').XF TEST FOR HLASM MNOTE 0,'THIS IS HIGH LEVEL ASSEMBLER' MEXIT .XF MNOTE 0,'THIS IS ASSEMBLER XF' MEND
I have tested the macro and it works as advertised for Assembler XF (IFOX00) and Assembler H (IEV90). It does not work for Assembler F (IEUASM from MVT), which issues several instances of the message IEU045 ILLEGAL SYMBOLIC PARAMETER. I don't have access to the High Level Assembler to test the macro's behavior there.
This question accompanied the previous question. In fact, further discussion in the Hercules-390 clarified that the question was intended to reference Assembler XF (IFOX00) rather than Assembler F (IEUASM from MVT). As far as I can determine from examining the source for IEUASM, there are no built-in symbolic variables provided for Assembler F. (I would gladly accept correction if I am wrong in this.)
Upon examination of the Assembler Language Reference manual and Assembler Programmer's Guide found at http://bitsavers.org/pdf/ibm/370/, I found the definition of these six built-in symbolic variables:
&SYSDATE the type attribute is always U; the count attribute is always eight; the value is an eight character string in the format 'MM/DD/YY' representing the value of the current system date. &SYSECT the type attribute is always U; the count attribute is equal to the number of characters assigned as a value to &SYSECT; the value assigned is the symbol that represents the name of the current control section from which the macro is called. &SYSLIST the variable refers to the complete list of positional operands specified in a macro instruction; the variable must be specified with one or more subscripts in order to evaluate to a specific positional parameter, or parameter list. &SYSNDX the type attribute is always N; the count attribute is always four; the value assigned is a four digit number, starting at 0001 the for the first macro called and incremented by 1 for each subsequent macro call. &SYSPARM the type attribute is always U; the count attribute is equal to the number of characters assigned as a value to &SYSPARM; the value assigned is taken from the character string specified for the value of SYSPARM in the PARM option on the EXEC JCL statement that invoked the assembler. &SYSTIME the type attribute is always U; the count attribute is always five; the value is a five character string in the format 'HH.MM' representing the value of the current system time.
This is confirmed by examination of the source for Assembler XF included with MVS 3.8j.
This error seems to occur most frequently with the free version of QWS3270. This client will work for the MVS console, but will cause this problem, and others, when used for a TSO session. You can probably get around this particular problem by setting the Yale Null Processing option (under the Options menu item) off. The default setting is on, which causes QWS3270 to translate all null characters (x'00') to space characters (x'40') before sending the terminal input data to the host. Setting the parameter off will cause QWS3270 to simulate a true 3270 terminal.
There are several free tn3270 clients available. See the x3270 page at sourceforge.
One of the marketing points for the S/360 architecture was upward compatibility. Programs written and compiled for a particular model would probably still execute correctly if you upgraded to a later model. Even though there are exceptions, you will probably find that it is still true.
The MVT Sort/Merge utility requires at least three (and may use up to a maximum of 32) intermediate storage datasets. Unlike current Sort/Merge utilities (such as DFSORT or Syncsort), the MVT Sort/Merge is unable to dynamically allocate datasets for use as intermediate storage. You must supply DD statements for the DD Names SORTWK01, SORTWK02, SORTWK03 ... SORTWK32. Also the SORTWK?? datasets must reside on 2311/2314 DASD. Although some efforts have been reported of using tape datasets with the MVT Sort/Merge under Hercules, it is probably a better idea to utilize DASD for the SORTWK?? datasets. If the MVT Sort/Merge is called indirectly (as by a COBOL program that includes the SORT verb), you must also supply SORTWK?? DD cards to the EXEC step.
[July 2020] If you are using an MVS system built following my instructions/tutorial to build an MVS 3.8j system, there are six 2314 DASD volumes defined as SORTW1 through SORTW6 and are assigned with the esoteric device name SORTDA.
[March 2024]
I have installed Tom Armstrong's completely rebuilt version 1.0 of OS/360 MVT Sort/Merge. It is an understatement to say that this is a great improvement over the original OS/360 version of the program. It will now dynamically allocate sort work datasets and is capable of utilizing any DASD type that it is possible to use under MVS 3.8j. If you have SYSCPK installed, you simply need to refresh your copy to the latest version to have this Sort/Merge available to use immediately. There is a PDS on SYSCPK - SYSC.SORT.CNTL - which contains Tom Armstrong's installation verification programs and a Programmers Guide for his version of the program that may be downloaded as a binary file to a host PC to view and/or print. You may also download the documentation from my site: Tom.Armstrong.OS.360.Sort.Merge.v01.1.Installation.Guide.pdf Tom.Armstrong.OS.360.Sort.Merge.v01.1.Application.Guide.pdf.
I have also updated the install tape for the OS/360 Sort/Merge to contain Tom Armstrong's version, but most people have already migrated to using SYSCPK, and it is not necessary to reload the Sort/Merge if you have SYSCPK installed.
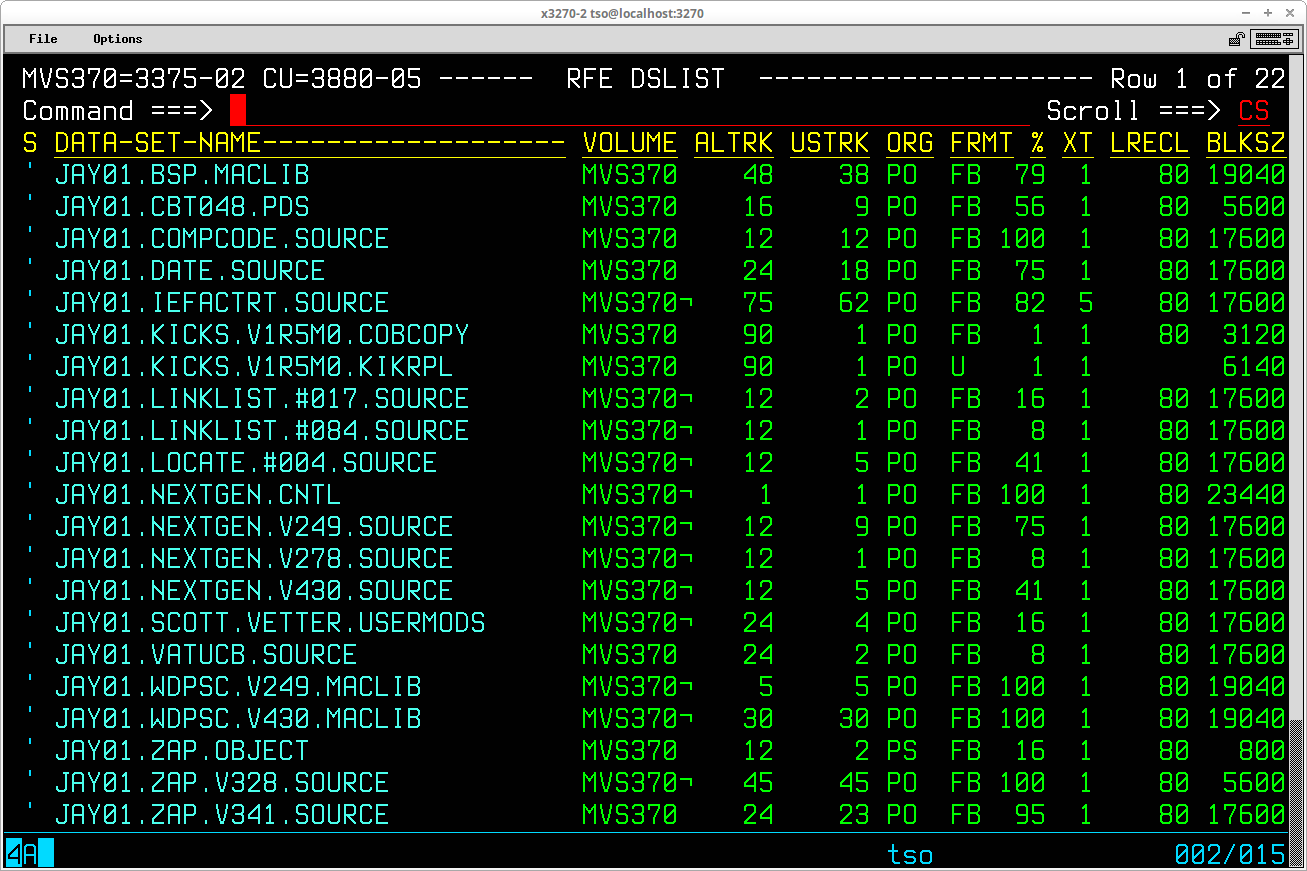
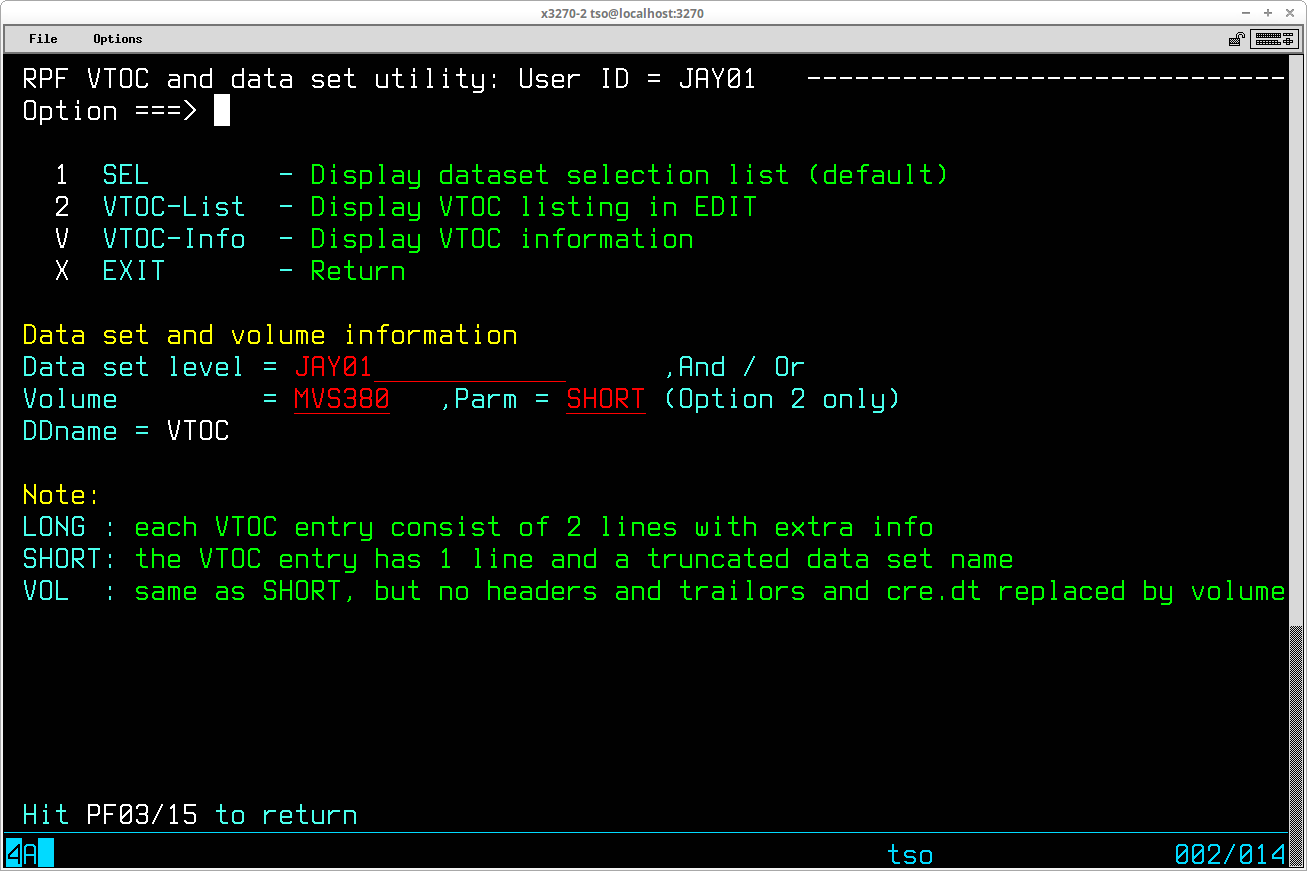
There are several ways to obtain this type of list.
From RPF, select 3.4 from the primary menu to display the VTOC and dataset utility panel:
To restrict the list of datasets to those containing a specified high level qualifier, enter the value of the qualifier desired in the Data set level = field (the default is the TSO User ID, so you must clear this field to obtain a listing of all datasets). Enter the volume serial number of the volume for which the datasets are to be listed in the Volume = field and press ENTER. The list of datasets will be displayed:
The two screen images above are from RPF version V1R8M0.
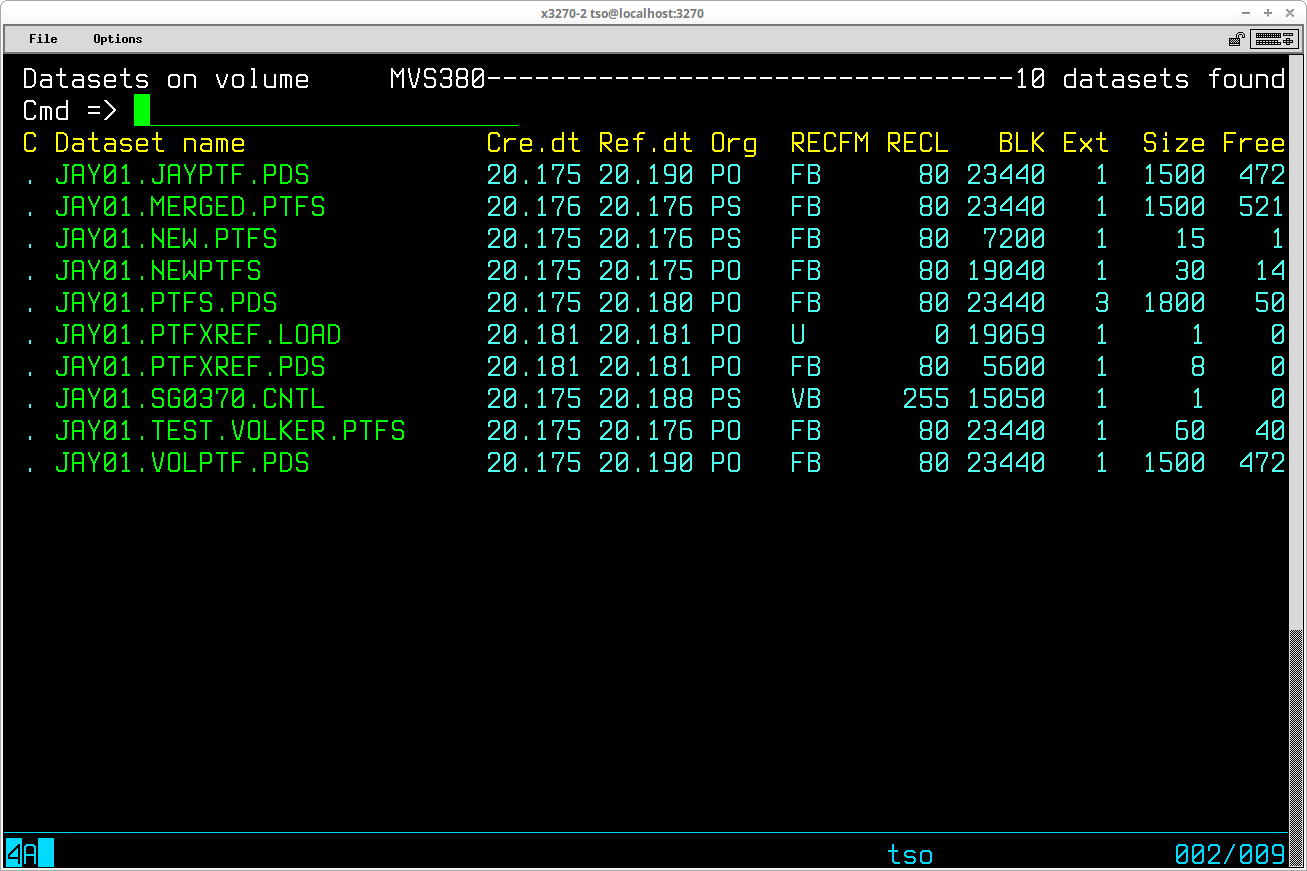
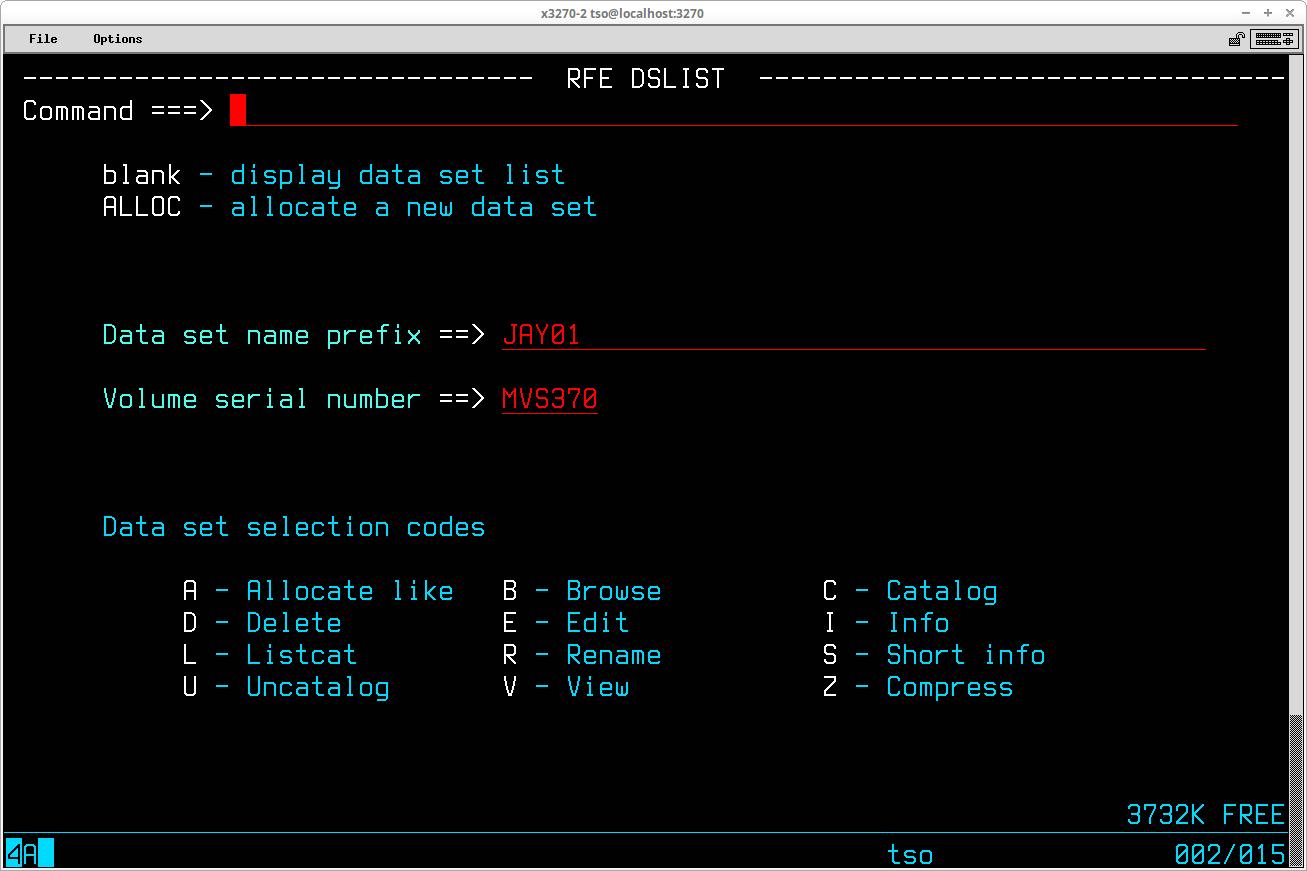
From RFE, select 3.4 from the primary menu to display the DSLIST panel:
To restrict the list of datasets to those containing a specified high level qualifier, enter the value of the qualifier desired in the Data set name prefix ==> field (RFE retains the contents of this field from the last time this panel was used in your REVPROF and will supply that value, so you may need to clear and re-enter this field to obtain the listing of datasets you wish to see). Enter the volume serial number of the volume for which the datasets are to be listed in the Volume serial number ==> field and press ENTER. The list of datasets will be displayed:
The logical not character (¬) displayed beside the Volume column for some datasets indicates that the particular dataset is not catalogued.
The two screen images above are from RFE version 49.5.
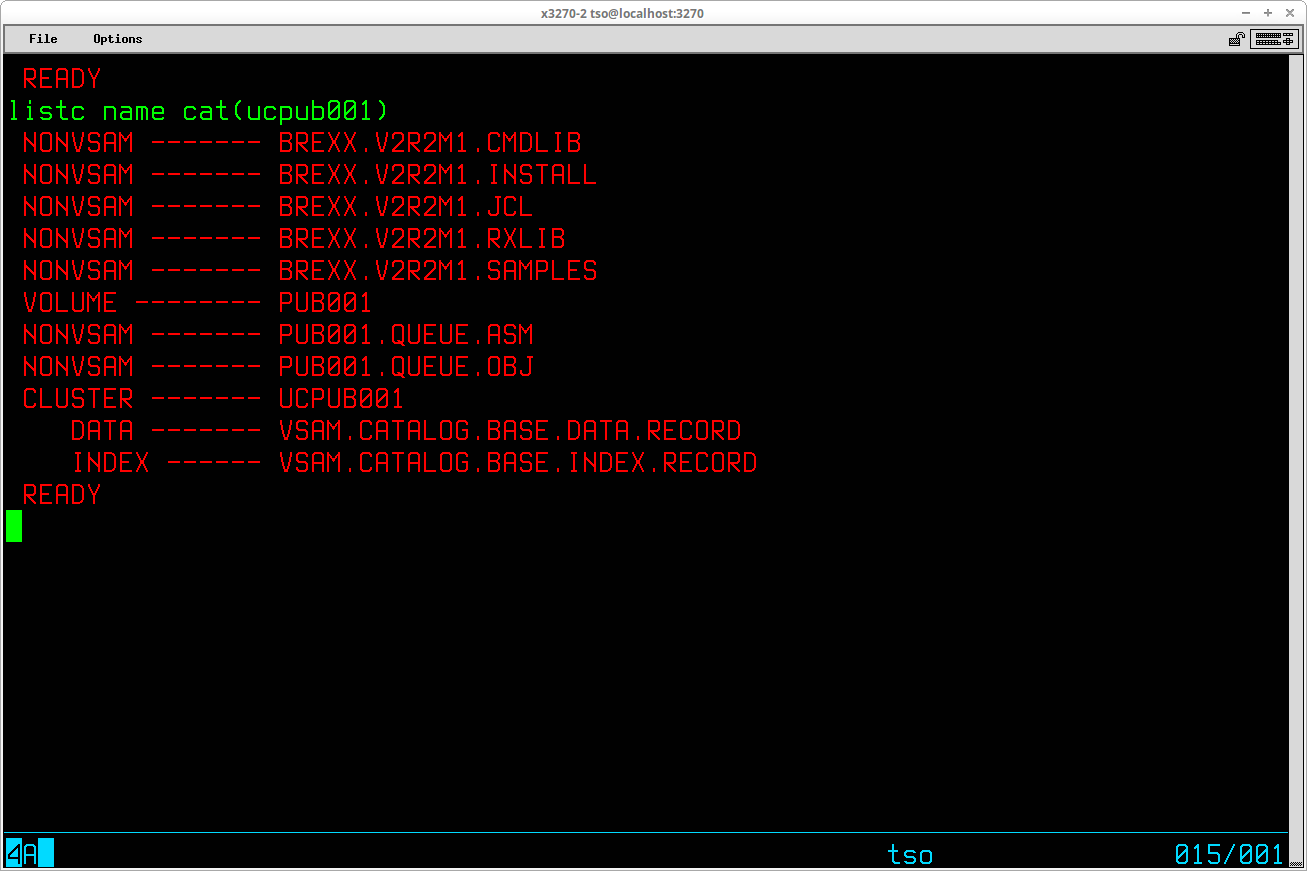
If you have set up User Catalogs for individual DASD volumes (a recommended practice), you can list the datasets that reside on a particular volume using the LISTCAT command from a TSO prompt:
There are three batch utilities that are specifically intended to list the datasets on a selected volume - IEHLIST (an IBM utility included with MVS), VTOCLIST (from the CBT tape) and SUPERLST (also from the CBT tape). A jobstream to execute IEHLIST is:
A jobstream to execute VTOCLIST is:
If you follow the link to either VTOCLIST or SUPERLST, there is an explanation for a procedure which will allow you to start a task from the console to list a specified volume without the necessity of editing/submitting a JCL member.
[July 2020] If you have SYSCPK installed on your system, VTOCLIST and SUPERLST are installed in SYSC.LINKLIB.
The coding in the application program is identical regardless of whether you wish to access the VSAM base cluster directly or through an Alternate Index. The mechanics of utilizing the Path and Alternate Index to access the base cluster are managed entirely by the VSAM Access Method transparently for your program. The single factor controlling whether the access is through the base cluster directly or the Path/Alternate Index is the Dataset Name coded on the DD statement in the Job Control Language. An example from James Martin's VSAM: Access Method Services and Programming Techniques illustrating this:
. . OPEN (KSDSACB) OPEN INPUT LTR 15,15 BNZ ERROR . . GET RPL=SEQRPL RETRIEVE RECORD SEQUENTIALLY LTR 15,15 BNZ ERROR . . CLOSE (KSDSACT) CLOSE INPUT LTR 15,15 BNZ ERROR . . SEQRPL RPL ACB=KSDSACB, C AREA=RECORD, C AREALEN=200, C OPTCD=(KEY,SEQ,NUP=MVE) RECORD DSL OCL200 RECORD WORK AREA PRODNO DS CL4 PRODUCT NUMBER (RECORD KEY) OHQUANT DS CL4 ON HAND QUANTITY DESCRIP DS CL20 PRODUCT DESCRIPTION PART DS 0CL4 PART NUMBER DS 42CL4 ROOM FOR 42 PARTS KSDSACB ACB DDNAME=KSDS, C MACRF=(KEY,SEQ,IN), C . .//KSDS DD DSN=INVENT.DESCRIP,DISP=SHR access is through Path/Alternate Index. . OPEN (KSDSACB) OPEN INPUT LTR 15,15 BNZ ERROR . . GET RPL=SEQRPL RETRIEVE RECORD SEQUENTIALLY LTR 15,15 BNZ ERROR . . CLOSE (KSDSACT) CLOSE INPUT LTR 15,15 BNZ ERROR . . SEQRPL RPL ACB=KSDSACB, C AREA=RECORD, C AREALEN=200, C OPTCD=(KEY,SEQ,NUP=MVE) RECORD DSL OCL200 RECORD WORK AREA PRODNO DS CL4 PRODUCT NUMBER (RECORD KEY) OHQUANT DS CL4 ON HAND QUANTITY DESCRIP DS CL20 PRODUCT DESCRIPTION PART DS 0CL4 PART NUMBER DS 42CL4 ROOM FOR 42 PARTS KSDSACB ACB DDNAME=KSDS, C MACRF=(KEY,SEQ,IN), C . .
I received this question from an individual coding a validation routine for United States' state abbreviation codes. They were receiving an error from TSO when attempting to use a comparison operator on the state codes for Nevada (NE) and Oregon (OR) since these abbreviations are identical to the Not Equal and Or comparison operator. The solution is to enclose both the variable and the literal in the CLIST inside of the &STR() function. The following example CLIST illustrates the correct coding:
Using the JOB name and system assigned JOB number, you can use the TSO OUTPUT command to retrieve the SYSOUT files from the JES2 Queue and place it into a dataset that can be viewed using RPF.
First you should allocate a dataset with the attributes RECFM=VBA and LRECL=137. If you don't allocate the dataset prior to issuing the OUTPUT command, the dataset will be allocated by the OUTPUT command, but the default amount of space may be inadequate for your JOB's output. The dataset name should be in the form of: <userid>.<jobname>.OUTLIST, where <userid> is your TSO USER ID and <jobname> is the JOB name.
Issue the TSO OUTPUT command to retrieve the SYSOUT files:
OUT <jobname>(Jnnnnn) PR(<jobname>) HOLD KEEP
In the command format shown above -
- <jobname>(Jnnnnn) must match the JOB name and system assigned JOB number and are used to retrieve the matching SYSOUT files from the JES2 queue
- PR(<jobname>) designates the destination dataset to receive the retrieved SYSOUT files; the fully qualified dataset name will be <userid>.<jobname>.OUTLIST
- HOLD KEEP prevent the purging of the files from the JES2 queue after they are copied to the dataset.
A more detailed discussion of the OUTPUT command may be read at TSO Tutorial: OUTPUT.
[July 2020] When using QUEUE to view spooled output in the JES2 queue, you may use the SAVE command to save the contents of the SYSOUT dataset being viewed. The command is: save <dataset name> where <dataset name> is the name for a dataset to be created to contain the output. The dataset will be RECFM=FBM with a LRECL=133. The dataset name specified should begin with your TSO User ID as the High Level Qualifier. Regardless of what is specified for the second qualifier, in my experience the second qualifier for the dataset will only be the first two characters that you specified, although a third qualifier will be used as specified.
Yes, here is an example program and the output (the output of the DISPLAY verb is written to the SYSOUT DD statement):
1 //COBCL JOB (001),'COBOL COMPILE',CLASS=A,MSGCLASS=X JOB 309 2 //GETPARM EXEC COBUCLG, 00020000 // PARM.GO='THIS PARAMETER PASSED ON THE EXEC STATEMENT.' 00030000 ==============================================================================================000100 IDENTIFICATION DIVISION. 000200 PROGRAM-ID. GETPARM. 000300 AUTHOR. JAY MOSELEY. 000400 DATE-WRITTEN. MARCH, 2008. 000500 DATE-COMPILED. MAR 22,1980 000700* ************************************************************* * 000800* RETRIEVE PARAMETER FROM MVS 'EXEC' STATEMENT. * 000900* ************************************************************* * 001100 ENVIRONMENT DIVISION. 001200 CONFIGURATION SECTION. 001300 SOURCE-COMPUTER. IBM-370. 001400 OBJECT-COMPUTER. IBM-370. 001500 001600 INPUT-OUTPUT SECTION. 001700 FILE-CONTROL. 001800 001900 DATA DIVISION. 002000 FILE SECTION. 002100 002200 WORKING-STORAGE SECTION. 002300 77 EDIT-LENGTH PIC Z,ZZ9. 002400 002500 LINKAGE SECTION. 002600 01 EXEC-PARAMETER. 002700 03 EXEC-PARAMETER-LENGTH PIC S9(4) COMP. 002800 03 EXEC-PARAMETER-VALUE PIC X(100). 002900 003000 PROCEDURE DIVISION USING EXEC-PARAMETER. 003100 003200 000-INITIATE. 003300 003400 DISPLAY 'GETPARM: EXECUTION BEGINNING'. 003500 DISPLAY '----------------------------'. 003600 003700 MOVE EXEC-PARAMETER-LENGTH TO EDIT-LENGTH. 003800 DISPLAY 'EXEC PARAMETER LENGTH: ' EDIT-LENGTH. 003900 004000 IF EXEC-PARAMETER-LENGTH GREATER THAN +0 004100 DISPLAY EXEC-PARAMETER-VALUE. 004200* END-IF. 004300 004400 020-TERMINATE. 004500 004600 DISPLAY '------------------------------'. 004700 DISPLAY 'GETPARM: EXECUTION TERMINATING'. 004800 004900 STOP RUN. 005000 ==============================================================================================GETPARM: EXECUTION BEGINNING ---------------------------- EXEC PARAMETER LENGTH: 44 THIS PARAMETER PASSED ON THE EXEC STATEMENT. ------------------------------ GETPARM: EXECUTION TERMINATING
Remember, there is a limitation of 100 characters on the data that may be passed in the PARM operand.
Yes, here is an example program followed by a dump of the tape contents:
1 //COBCLG JOB (001),'COBOL COMPILE',CLASS=A,MSGCLASS=X JOB 313 2 //USRLABEL EXEC COBUCLG 00020002 11 //COB.SYSIN DD DSN=JAY01.SOURCE(USRLABEL),DISP=SHR 00040002 20 //GO.SYSUT1 DD UNIT=TAPE,LABEL=(1,SUL),DISP=(NEW,KEEP), 00050002 // VOL=SER=999999,DSN=TEST.USER.LABELS 00060002 ============================================================================================= 000100 IDENTIFICATION DIVISION. 000200 PROGRAM-ID. USRLABEL. 000300 AUTHOR. JAY MOSELEY. 000400 DATE-WRITTEN. MARCH, 2008. 000500 DATE-COMPILED. MAR 23,1980 000700* ************************************************************* * 000800* WRITE USER HEADER AND TRAILER LABELS ON OUTPUT TAPE. * 000900* ************************************************************* * 001100 ENVIRONMENT DIVISION. 001200 CONFIGURATION SECTION. 001300 SOURCE-COMPUTER. IBM-370. 001400 OBJECT-COMPUTER. IBM-370. 001500 001600 INPUT-OUTPUT SECTION. 001700 FILE-CONTROL. 001800 001900 SELECT OUTPUT-TAPE-FILE 002000 ASSIGN TO UT-S-SYSUT1. 002100 002200 DATA DIVISION. 002300 FILE SECTION. 002400 FD OUTPUT-TAPE-FILE 002500 LABEL RECORDS ARE USER-LABEL-RECORD 002600 RECORD CONTAINS 80 CHARACTERS 002700 BLOCK CONTAINS 39 RECORDS 002800 DATA RECORD IS DATA-RECORD. 002900 003000 01 DATA-RECORD. 003100 03 DR-ID PIC X(19). 003200 03 DR-POSITION PIC 9(03). 003300 03 FILLER PIC X(58). 003400 003500 01 USER-LABEL-RECORD. 003600 03 ULR-ID PIC X(03). 003700 03 ULR-POSITION PIC 9(01). 003800 03 ULR-DATA PIC X(76). 003900 004000 WORKING-STORAGE SECTION. 004100 77 UHL-COUNTER PIC S9(1) VALUE +0. 004200 77 UTL-COUNTER PIC S9(1) VALUE +0. 004300 77 RECORD-COUNTER PIC S9(3) VALUE +0. 004400 77 COUNTER-EDIT PIC ZZ9. 004500 004600 PROCEDURE DIVISION. 004700 DECLARATIVES. 004800 USER-HEADER-LABEL SECTION. 004900 USE AFTER BEGINNING FILE LABEL PROCEDURE ON OUTPUT-TAPE-FILE. 005000 USER-HEADER-LABEL-PROCEDURE. 005100 IF UHL-COUNTER < +2 005200 ADD +1 TO UHL-COUNTER 005300 MOVE 'UHL' TO ULR-ID 005400 MOVE UHL-COUNTER TO ULR-POSITION 005500 MOVE 'USER HEADER LABEL CONTENT FORMATTED BY USER' 005600 TO ULR-DATA 005700 GO TO MORE-LABELS. 005800* END-IF. 005900 006000 USER-TRAILER-LABEL SECTION. 006100 USE AFTER ENDING FILE LABEL PROCEDURE ON OUTPUT-TAPE-FILE. 006200 USER-TRAILER-LABEL-PROCEDURE. 006300 IF UTL-COUNTER < +2 006400 ADD +1 TO UTL-COUNTER 006500 MOVE 'UTL' TO ULR-ID 006600 MOVE UTL-COUNTER TO ULR-POSITION 006700 MOVE 'USER TRAILER LABEL CONTENT FORMATTED BY USER' 006800 TO ULR-DATA 006900 GO TO MORE-LABELS. 007000* END-IF. 007100 END DECLARATIVES. 007200 007300 000-MAIN-PROCESS. 007400 007500 OPEN OUTPUT OUTPUT-TAPE-FILE. 007600 PERFORM 100-WRITE-DATA 99 TIMES. 007700 CLOSE OUTPUT-TAPE-FILE. 007800 STOP RUN. 007900 008000 100-WRITE-DATA. 008100 ADD +1 TO RECORD-COUNTER. 008200 MOVE SPACES TO DATA-RECORD. 008300 MOVE 'DATA RECORD NUMBER' TO DR-ID. 008400 MOVE RECORD-COUNTER TO DR-POSITION. 008500 WRITE DATA-RECORD. 008600 ============================================================================================= VOL19999990 HERCULES HDR1TEST.USER.LABELS 99999900010001 80083 000000000000IBM OS/VS 370 HDR2F031200008040COBCLG /GO B 30001 UHL1USER HEADER LABEL CONTENT FORMATTED BY USER UHL2USER HEADER LABEL CONTENT FORMATTED BY USER UHL3USER HEADER LABEL CONTENT FORMATTED BY USER TAPE MARK DATA RECORD NUMBER 001 DATA RECORD NUMBER 002 DATA RECORD NUMBER 003 DATA RECORD NUMBER 004 DATA RECORD NUMBER 005 DATA RECORD NUMBER 006 DATA RECORD NUMBER 007 DATA RECORD NUMBER 008 DATA RECORD NUMBER 009 DATA RECORD NUMBER 010 DATA RECORD NUMBER 011 DATA RECORD NUMBER 012 DATA RECORD NUMBER 013 DATA RECORD NUMBER 014 DATA RECORD NUMBER 015 DATA RECORD NUMBER 016 DATA RECORD NUMBER 017 DATA RECORD NUMBER 018 DATA RECORD NUMBER 019 DATA RECORD NUMBER 020 DATA RECORD NUMBER 021 DATA RECORD NUMBER 022 DATA RECORD NUMBER 023 DATA RECORD NUMBER 024 DATA RECORD NUMBER 025 DATA RECORD NUMBER 026 DATA RECORD NUMBER 027 DATA RECORD NUMBER 028 DATA RECORD NUMBER 029 DATA RECORD NUMBER 030 DATA RECORD NUMBER 031 DATA RECORD NUMBER 032 DATA RECORD NUMBER 033 DATA RECORD NUMBER 034 DATA RECORD NUMBER 035 DATA RECORD NUMBER 036 DATA RECORD NUMBER 037 DATA RECORD NUMBER 038 DATA RECORD NUMBER 039 DATA RECORD NUMBER 040 DATA RECORD NUMBER 041 DATA RECORD NUMBER 042 DATA RECORD NUMBER 043 DATA RECORD NUMBER 044 DATA RECORD NUMBER 045 DATA RECORD NUMBER 046 DATA RECORD NUMBER 047 DATA RECORD NUMBER 048 DATA RECORD NUMBER 049 DATA RECORD NUMBER 050 DATA RECORD NUMBER 051 DATA RECORD NUMBER 052 DATA RECORD NUMBER 053 DATA RECORD NUMBER 054 DATA RECORD NUMBER 055 DATA RECORD NUMBER 056 DATA RECORD NUMBER 057 DATA RECORD NUMBER 058 DATA RECORD NUMBER 059 DATA RECORD NUMBER 060 DATA RECORD NUMBER 061 DATA RECORD NUMBER 062 DATA RECORD NUMBER 063 DATA RECORD NUMBER 064 DATA RECORD NUMBER 065 DATA RECORD NUMBER 066 DATA RECORD NUMBER 067 DATA RECORD NUMBER 068 DATA RECORD NUMBER 069 DATA RECORD NUMBER 070 DATA RECORD NUMBER 071 DATA RECORD NUMBER 072 DATA RECORD NUMBER 073 DATA RECORD NUMBER 074 DATA RECORD NUMBER 075 DATA RECORD NUMBER 076 DATA RECORD NUMBER 077 DATA RECORD NUMBER 078 DATA RECORD NUMBER 079 DATA RECORD NUMBER 080 DATA RECORD NUMBER 081 DATA RECORD NUMBER 082 DATA RECORD NUMBER 083 DATA RECORD NUMBER 084 DATA RECORD NUMBER 085 DATA RECORD NUMBER 086 DATA RECORD NUMBER 087 DATA RECORD NUMBER 088 DATA RECORD NUMBER 089 DATA RECORD NUMBER 090 DATA RECORD NUMBER 091 DATA RECORD NUMBER 092 DATA RECORD NUMBER 093 DATA RECORD NUMBER 094 DATA RECORD NUMBER 095 DATA RECORD NUMBER 096 DATA RECORD NUMBER 097 DATA RECORD NUMBER 098 DATA RECORD NUMBER 099 TAPE MARK EOF1TEST.USER.LABELS 99999900010001 80083 000000000003IBM OS/VS 370 EOF2F031200008040COBCLG /GO B 30001 UTL1USER TRAILER LABEL CONTENT FORMATTED BY USER UTL2USER TRAILER LABEL CONTENT FORMATTED BY USER UTL3USER TRAILER LABEL CONTENT FORMATTED BY USER TAPE MARK TAPE MARK
Note that the DD Statement for the tape must specify SUL (Standard User
Labels) or the program will execute, but the User Labels will not be
written to the tape (thanks to Roger Bowler for supplying this
information).
In the Declaratives paragraph where the User Labels are formatted, the special
exit signified by "GO TO MORE-LABELS" causes the compiler to generate
the correct code to write the formatted label record and branch back to the
beginning of the paragraph to process additional labels.
Yes, although it may not include some extensions that are available with the latest versions of COBOL compilers. However, it is my understanding that some compiler manufacturers removed the Report Writer Feature, so in some comparisons the OS/360 MVT COBOL compiler may have more functionality than the latest and greatest version. I have written a tutorial covering the basics of using the Report Writer Feature, with examples at: COBOL Report Writer.
In 1970, M. M. Kessler wrote a report describing the implementation of a method of writing structured Assembler code by utilizing a set of macros. These macros are what became referred to as the Concept 14 Macros, and they developed some community of followers. There have been other sets of macros developed to provide a similar function, but these were the first. You can obtain an IEBUPDTE jobstream to install the macros, and also view a scanned copy of the original report at https://skycoast.us/pscott/software/mvs/concept14.html, a website maintained by Paul A. Scott. Checking this in February, 2014, I see that there is very little left at this site; apparently the Concept 14 macros may be found at the CBT Tape site in File #316 under the entry: STRMACS.
[July 2020] If you have SYSCPK installed on your system, the Concept 14 macro library is included in the dataset: SYSC.CONCEPT.#14.MACLIB and another structured programming macro library is included in the dataset: SYSC.CLEMSON.MACLIB.
I have received this question several times over the years. While compiling an RPG program there are a number of confusing errors issued, usually about the Input Specification cards and most often mentioning the STERLING specification being invalid. The most common reason for this is that sequence numbers have been inserted in the right-most columns of the RPG input source. RPG expects sequence numbers to only appear in columns 1 through 6, although they are optional. But several of the RPG specification formats extend beyond column 70, so if you have edited your source and have not turned off standard sequencing in columns 73 through 80, this is going to be an error you will see.
Re-edit your source, carefully remove the sequence numbers - because there may be some valid RPG entries in columns 71 through 74 in some of the specification formats - and try running your compile again.
If you need to have JES2 prompt for a form change for a SYSOUT dataset, code the four character form designation on the SYSOUT DD statement:
In the example statement above, the first parameter inside the parentheses specifies the output class, the second (omitted) parameter would specify the writer name, and the third parameter specifies the four character form designation.
The DASD volume to be changed must be attached to Hercules and varied offline.
If you are using an MVS 3.8j system built using my instructions, there is a CLIP utility installed to do this:
From the MVS console, issue the command: s clip,u=[uuu],v=[vvvvvv] where uuu specifies the unit address and vvvvvv specifies the new Volume Serial number.
If you do not have the CLIP utility installed, you may use the following ICKDSF job to accomplish the same function:
[February 2025] I had been using the CLIP utility for a very long time whenever I needed to change the Volume Serial of a DASD image. However, recently I found myself needing to retrieve several DASD images from a Host OS backup set in order to retrieve specific MVS datasets that I had been a bit hasty in deleting or changing on the MVS side. I thought, why isn't there a way to change the Volume Serial in the DASD image file from Linux. So I did a bit of poking about with a hex editor and developed a REXX script to do just that. You can download a copy of the script from dasdvolser.rexx, save it with your other Hercules' binaries and it might be useful to you when you find yourself in a similar situation. I did add the VER option, primarily for use in conjunction with the REP option, just to be sure you are changing the Volume Serial number in the correct position in the image file.
Most often the requirement is for a COBOL program to call an Assembler program to provide a function that is beyond COBOL syntax, but sometimes there is a requirement for an Assembler main program to call a COBOL subprogram.
I have written Assembler and COBOL programs to illustrate how to accomplish this type of call. There are two situations for which examples are provided.
The first situation is a Static call. In a Static call, the object modules for both the calling and called program are assembled/compiled and the object modules are link-edited together to form a single load module. The subprogram being called is, by definition, available at compile time and will not change from compile time to execution time. This is illustrated by the job output asm2cobs.pdf. In the Assembler main program, statement 78:
CALL COBSUB,(VAR01,VAR02,VAR03,VAR04)
transfers control to the COBOL subprogram named COBSUB (sorry my name choices are not more creative), and passes the addresses of four variables to the subprogram. Note that any modification to the contents of the variables made by the COBOL subprogram are made to the storage defined in the Assembler main program, which I have shown by using DISPLAY statements (and corresponding Assembler syntax to write to the log) to show the contents of the four variables before, during, and after the subprogram is called.
The second situation is a Dynamic call. In a Dynamic call, the subprogram is compiled separately from the main program into a load module that is stored in a library which will be available at execution time. There is no requirement to recompile the subprogram whenever the main program is Assembled. This is illustrated by the job oubput asm2cobd.pdf. In the Assembler main program, statement 81:
LOAD EPLOC=COBSUB
fetches the COBSUB program's load module into main memory. The subprogram's load module may reside in any library which is available to load modules from at the time the load module for the Assembler main program is executed. After the program is loaded into memory, Register 1 is loaded with a list of parameters to be passed to the subprogram (statement 86) and control is transferred to the subprogram in memory (statements 87 and 88).
Note that the identical COBOL subprogram is used for both examples. Although the COBOL subprogram is compiled and link-edited to a library for the second (Dynamic) example, the COBOL program will not execute on its own as a main program.
Also note that in the second (Dynamic) example, for simplicity I compile and link-edit the COBOL subprogram and Assemble and execute the Assembler main program in a single jobstream. However, the COBOL subprogram does not exist in any form in the load module created from the Assembler main program.
The two jobstreams are available from asm2cob.tar.gz and should execute with no problem on any system where SYSCPK is installed.
I hope that you have found my instructions useful. If you have questions that I can answer to help expand upon my explanations and examples shown here, please don't hesitate to send them to me:

This page was last updated on February 25, 2025 .