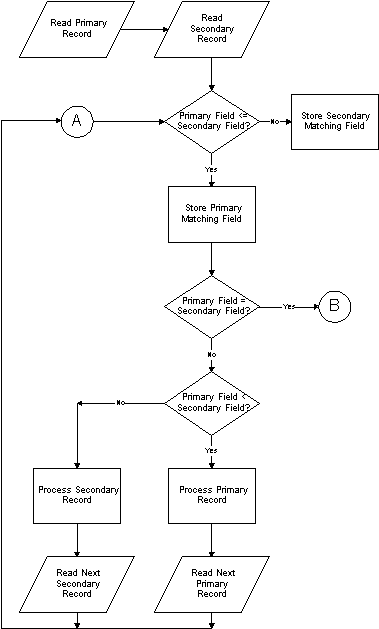
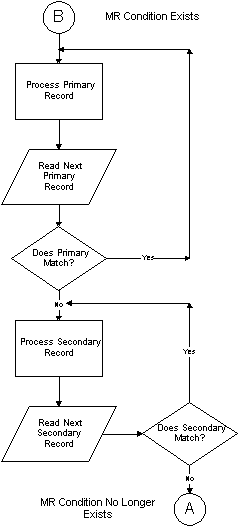
The matching records capability of RPG provides the means to process records from two or more files sequentially, performing operations when records from multiple files contain identical data in the specified matching fields.
I personally have not used matching records a great deal, having relied much more heavily upon random processing, especially with the advent of VSAM. However, using matching records in RPG is much easier to implement than writing an equivalent COBOL program to accomplish a multi-file match/merge. Even when records are contained in an indexed file organization (ISAM or VSAM), if the majority of records are likely to be updated, it would make more sense from a processing overhead standpoint to process the files sequentially. Matching records is the perfect solution for such updates.
The basic concept of matching records is simple - only one record is the "active" record at a particular time in the RPG logic cycle, however the "next" record from each input file is available at the beginning of the record selection cycle. Therefore, the RPG program can indicate, via MR (the matching record indicator), if the currently selected record contains matching records in the other input files.
As many as three fields may be specified as matching fields in a single program. Input fields are designated as matching fields by the inclusion of M1, M2, or M3 in columns 61-62 of the Input specification. If more than M1 is specified, the three data fields are considered by the RPG program as a single logical field for the purpose of comparing to the corresponding fields in each input file. In RPG I, the three fields must be specified in the order they occur in the record, ie the field designated M1 must be to the left of the field designated M2, and the field designated M2 must be to the left of the field designated M3.
The order of hierarchy by which records are selected for processing is determined by the order in which files are specified in the File Specifications. The primary file has the highest precedence, followed by the first secondary, followed by the next secondary, etc. Without using matching records, all of the records from the primary file are processed before any records are processed from the first secondary. Then all of the records from the first secondary file are processed, and so on.
Using matching records, the file from which the next record is selected for processing depends upon both the file specification order and the condition of whether the designated matching fields contain identical data. The order in which records are processed from two input files, using matching records, can be illustrated by this flowchart:
You can download a PDF containing this flowchart from rpgmr.pdf.

This page was last updated on January 17, 2015.